Abstract.
Multimodal immersive spatial drama generation focuses on creating continuous multi-speaker binaural speech with dramatic prosody based on multimodal prompts,
with potential applications in AR, VR, and others. This task requires simultaneous modeling of spatial information and dramatic prosody based on multimodal inputs,
with high data collection costs. To the best of our knowledge, our work is the first attempt to address these challenges.
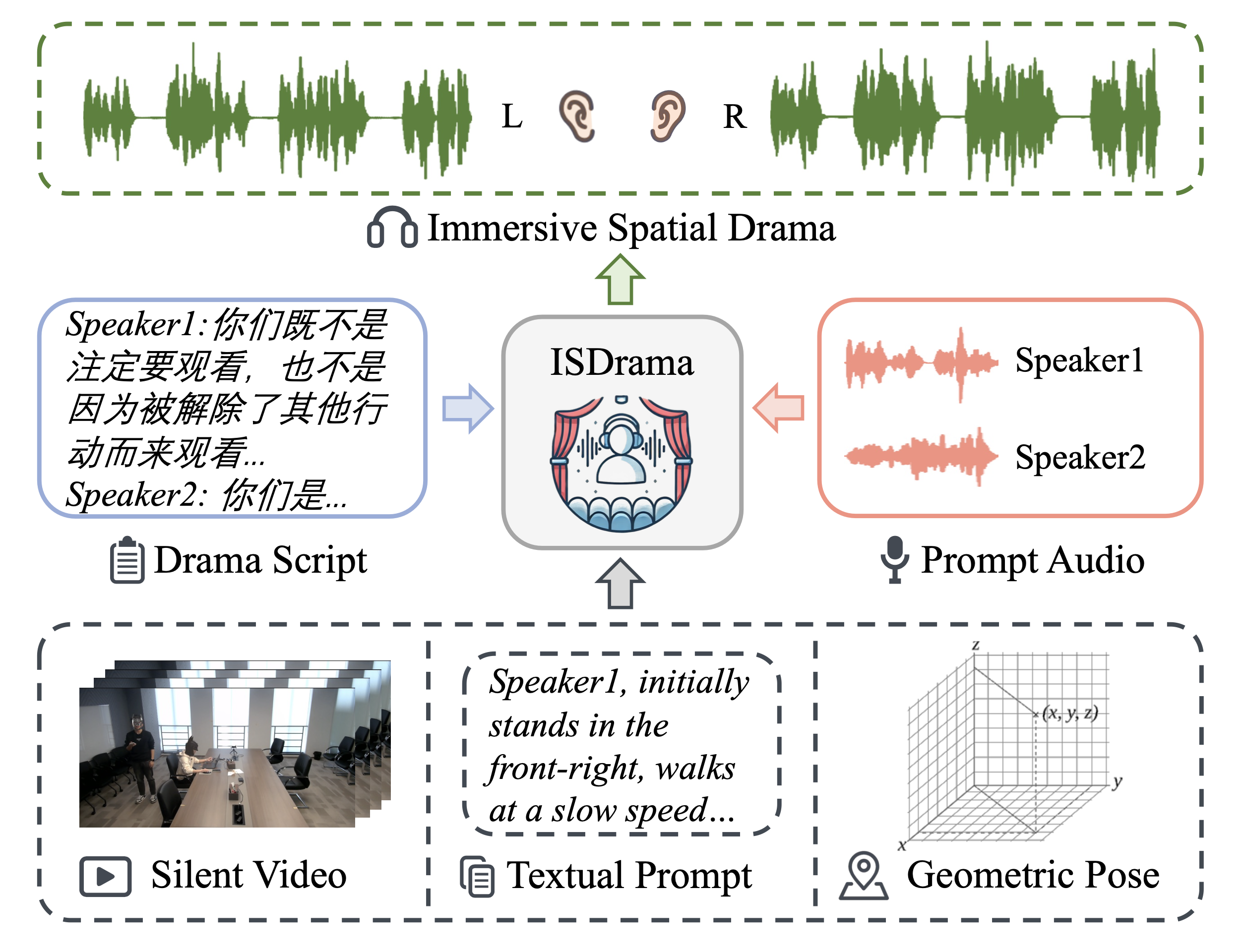
We construct MRSDrama, the first multimodal recorded spatial drama dataset, containing binaural drama audios, scripts, videos, geometric poses,
and textual prompts. Then, we propose ISDrama, the first immersive spatial drama generation model through multimodal prompting.
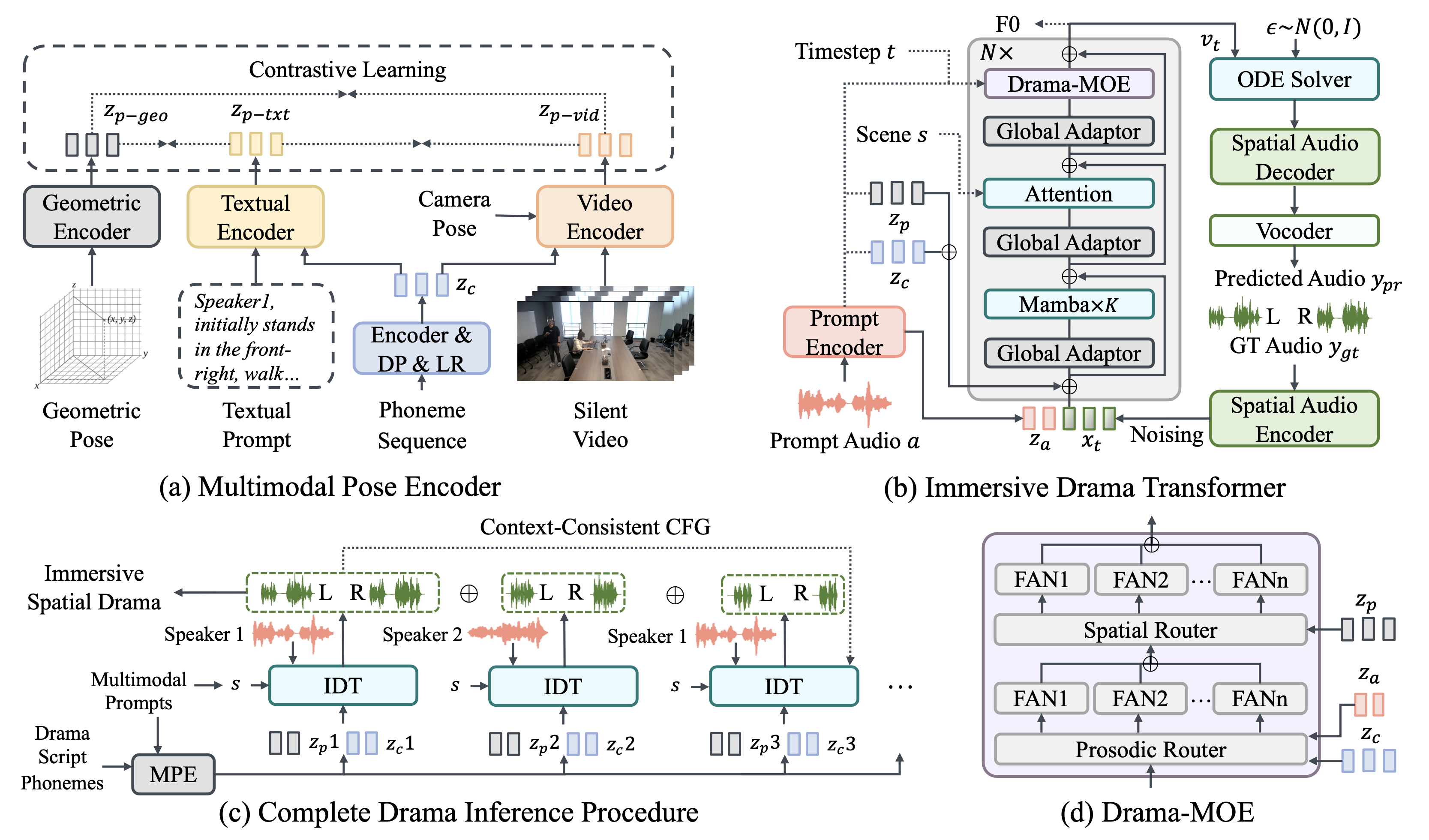
ISDrama comprises these primary components: 1) Multimodal Pose Encoder, based on contrastive learning,
considering the Doppler effect caused by moving speakers to extract unified pose information from multimodal prompts.
2) Immersive Drama Transformer, a flow-based mamba-transformer model that generates high-quality drama, incorporating Drama-MOE to select proper experts for enhanced prosody and pose control.
We also design a context-consistent classifier-free guidance strategy to coherently generate complete drama. Experimental results show that ISDrama outperforms baseline models on objective and subjective metrics.
Model Overview
In this paper, we first introduce MRSDrama, the first multimodal recorded spatial drama dataset, comprising binaural drama audios, scripts, videos, geometric poses, and textual prompts.
The dataset includes 97.82 hours of speech data recorded by 21 speakers across three scenes.
Next, we propose ISDrama, the first immersive spatial drama generation model based on multimodal prompting.
ISDrama generates high-quality, continuous, multi-speaker binaural speech with dramatic prosody and spatial immersion, driven by multimodal prompts.
To extract a unified pose representation from multimodal prompts, we design the Multimodal Pose Encoder, a contrastive learning-based framework that encodes not only position and head orientation but also radial velocity, accounting for the Doppler effect caused by moving speakers.
Meanwhile, we develop the Immersive Drama Transformer, a flow-based Mamba-Transformer model capable of generating immersive spatial drama effectively and stably.
Within this model, we introduce Drama-MOE (Mixture of Experts), which selects the appropriate experts to enhance prosodic expressiveness and improve pose control.
Then, we adopt a context-consistent classifier-free guidance (CFG) strategy to ensure the quality and coherence of complete drama generation.
🎧🎧🎧 Please use ear phones to listen to the generated audio samples. 🎧🎧🎧
🎙️🎙️🎙️For Fair Comparison, all samples are resampled to 48kHZ.🎙️🎙️🎙️
In this section, we present generated samples of continuous multi-speaker binaural speech with dramatic prosody with silent video input.
We input the drama script as content, the prompt audios to specify timbres of different speakers, the silent video (and camera direction) as the pose prompt and scene information, then ISDrama generates the immersive spatial drama.
Demo1: Henry IV
Audio Prompt Input
Speaker1:Speaker2:
Speaker3:Speaker4:
Generated Binaural Audio with Silent Video
Demo2: Waiting for Godot
Audio Prompt Input
Speaker1:Speaker2:Speaker3:
Generated Binaural Audio with Silent Video
Demo3: Troilus and Cressida
Audio Prompt Input
Speaker1:Speaker2:
Speaker3:Speaker4:
Generated Binaural Audio with Silent Video
Geometric Pose Generation Results
In this section, we present generated samples of single binaural speech with dramatic prosody for better comparison with baseline models.
We input the drama script as content, the prompt audios to specify timbre, geometric pose (3D position and quaternion orientation) as the pose prompt, and scene information, then ISDrama generates the binaural audio.
The actual geometric pose is provided as frame-level sequences, and here we present the video for better understanding.
Audio Quality: Successfully learn timbre and prosody from audio prompts, and effectively generate regretful emotions that align with the script content;
Spatialization: Compared to other baselines, our model achieves smoother and more natural motion from left to right, providing enhanced pose perception.
Voice Quality: Successfully transfer timbre information from audio prompts to the synthesized audio, generating smooth and natural sentences with a hint of sarcastic and teasing emotion;
Spatialization: Our model successfully control the natural change in sound as the speaker moves from back to front, providing listeners with a more realistic pose perception.
Voice Quality: Successfully transfer the timbre and pronunciation, achieving a deep and sorrowful emotion that aligns with the script content;
Spatialization: Our model effectively models the spatial information of the speaker pacing from right to left, achieving a natural and realistic spatial positioning effect.
Demo4: Waiting for Godot
Audio Prompt Input
Audio Prompt:
Script Input
不,不,咱们也许可以从头再来一遍。
ISDrama(ours)
CosyVoice
FireRedTTS
F5-TTS
Voice Quality: Successfully transfer the timbre and pronunciation demonstrated in the audio prompts, generating high-expressiveness speech with an anxious emotion that aligns with the script content;
Spatialization: Our model authentically reflects the speaker's rapid position changes moving from left to right, with the synthesized audio providing smoother and more natural spatial perception.
Textual Prompt Generation Results
In this section, we present generated samples of continuous multi-speaker binaural speech with dramatic prosody with textual prompts.
We input the drama script as content, the prompt audios to specify timbres of different speakers, textual prompt for each actor's line as the pose prompt, and scene information, then ISDrama generates the immersive spatial drama.
Demo1: Offending the Audience
Prompt Audio Input
Speaker1:Speaker2:
Generated Binaural Audio
Textual Prompt and Script Input
Speaker 1(walks from back-right to back-left, with intermittent pauses):
这里没有叫喊的寂静。这里没有寂静的寂静。这里没有死一般的寂静。在这里,通过说话并不产生沉默。这剧本中没有指令要求我们保持沉默。我们说话时不做任何故意的停顿。我们的停顿都是自然的停顿。我们的停顿并不像沉默那样富有说服力。通过沉默我们不会说出任何东西。我们之间的话语并不会出现深渊。我们之间的话语不存在裂缝。你们不可能在句号之间进行阅读。
Speaker 2(sits at front-right):
从我们的脸上,你们读不出任何东西。与之相关,我们的手势不会表达任何东西。在这里,通过沉默表达出来的并不是不可说的东西。
Demo2: Hiroshima Mon Amour
Prompt Audio Input
Speaker1:Speaker2:
Generated Binaural Audio
Textual Prompt and Script Input
Speaker 1(stands at front-right and intermittently moves): 广岛有医院。我怎么能对此避而不见呢?
Speaker 2(sits at front-left): 广岛的哪个博物馆?
Speaker 1(slowly moves from front-right to back-right): 在广岛,我曾四次去博物馆。我看见一些人在那里徘徊。因为没有别的东西,人们若有所思地在一幅幅画面和一件件复制品之间徘徊;因为没有别的东西,只能在一幅幅照片、一幅幅照片和一件件复制品之间徘徊;因为没有别的东西,只能在解说牌之间徘徊。
Speaker 2(sits at front-left): 你在广岛什么也不曾看见,一无所见。
Speaker 1 (walks from back-right to back-left): 复制品做得尽可能逼真。影片拍摄得尽可能逼真。那幻景,显而易见的,是那样逼真,以至游客都潸然泪下。人们依然会满不在乎,然而,对此情此景,一个游客除了哭泣,还能做什么呢?不仅仅是哭泣而已,以便忍受所见所闻中的这番惨景。还有,伤心够了走出博物馆,却不至于丧失理智。
Demo3: Waiting for Godot
Prompt Audio Input
Speaker1:Speaker2:
Generated Binaural Audio
Drama Script Input
Speaker 1((sits at near front-left))
你走不远的。
Speaker 2(stands at back-right and intermittently moves):
那太糟糕啦,实在太糟糕啦!你说呢,狄狄,是不是实在太糟糕啦?当你想到路上的景色是多么美丽。还有路上的行人是多么善良。你说是不是,狄狄?
Speaker 1:
你要冷静些。
Speaker 2(stands at back-right):
冷静……所有的上等人都说要冷静。
Speaker 1:
别说啦!
Speaker 2(walks from back-right to back-left):
有个英国人多喝了点儿酒,走进一家妓院。舅母问他要漂亮的、黑皮肤的还是红头发的。你说下去吧。
Speaker 1:
别说啦!
Speaker 2(stands at back-left):
你是要跟我说话吗?你有话要跟我说吗?狄狄……
Speaker 1:
我没有什么话要跟你说。
Speaker 2(stands at back-left and intermittently moves):
你生气了?原谅我。来吧,狄狄。把你的手给我。拥抱我!你一股大蒜臭!